The Agile movement shifted the industry’s approach to testing software. Some of that shift was greatly needed. But some of it was deeply misguided, and has resulted in enormous dysfunction that is still present today.
When we talk about testing, we are really talking about product validation, because testing is only one technique for validating that a product achieves its goals, or even works as expected. For example, small software modules can be verified using mathematical proofs: for those, testing is superfluous. And many years ago IBM discovered that their “software clean room” method resulted in code that was more defect-free than thoroughly tested software.
Testing is Risk Management
We point this out to emphasize what our actual goal is with testing: to convince us that the product will do what we want it to do, reliably. Testing is not the goal: validating the product is the goal. Fundamentally, testing is a technique for reducing risk: reducing the risk that the product will not do what we expect it to do.
Testing is not the goal: validating the product is the goal.
Importantly, more testing is not always better. For each system there is an optimal balance: how much effort to invest in designing, and how much to invest in testing. It depends on the risk: the risk that the product will not do what you want it to do, reliably.
What Continuous Delivery Did
The advent of continuous delivery (CD), in effect, shifted risk management to real time, by making integration tests automated and encouraging people to run them frequently, from the start of work through to the end, instead of only at the end. Thus, instead of relying on attestation “gates” for deployment, a system is deemed good to deploy if all the automated tests pass.
For that approach to work, there needs to be confidence that the tests are complete enough and that we have the right level of testing – appropriate for the risk.
For continuous delivery to work, there needs to be confidence that the tests are complete enough – but code coverage only applies to unit tests.
Yet that is where the Agile and DevOps community have largely been silent. Cliff is one of the few people we know who has written about how to manage test coverage above the unit level. (For example, see this article series by Cliff and Scott Barnes: https://www.transition2agile.com/2014/12/real-agile-testing-in-large.html).
Ideas That Are Out of Date
One prevalent testing idea that is out of date is the testing pyramid. The testing pyramid says that most of one’s tests should be at the unit level. Would unit testing have prevented the disastrous CloudStrike incident in July 2024? It is very doubtful: that appeared to be an integration issue (see Andrew’s detailed analysis of that incident).
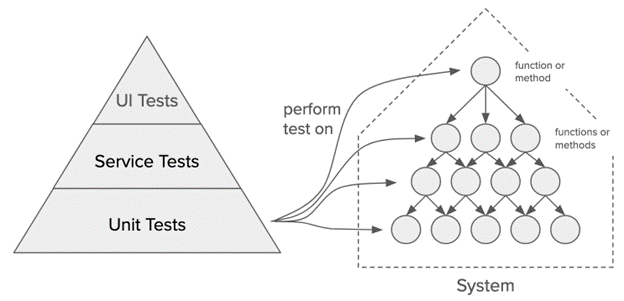
Figure: testing pyramid and a monolithic system. The circles are functions or methods.
The testing pyramid was developed at a time when systems were monolithic. Many of today’s systems are not monolithic: instead, they are highly distributed. At one of Cliff’s clients, he obtained a list of all of the production incidents that had occurred in the client’s microservice-based systems for one year, and identified the root cause of each failure. Cliff discovered that only 20% of the failures would have been caught by unit tests: all of the remainder were integration-related. And this was in an organization that had advanced practices for API management.
The testing pyramid was developed at a time when systems were monolithic.
Thus, for today’s distributed systems, integration tests are far more important, from a risk management perspective. For highly distributed systems, we actually need more of a test “diamond”: most of the tests should be integration tests that call the various microservices. (In the figure below, these are labeled “Service Tests”.)
In fact, Cliff did a study of this, by obtaining incident reports for all incidents of a cloud and microservice based system, spanning one year. Examination of the incident causes revealed that 80% of them were integration related, and would not have been detected by unit tests.
Integration tests are the ones that test interactions among the distributed components, which is where most of the problems tend to be in a distributed system. (In the figure below, the service tests and component interactions are shown in red.) UI tests do that too, but they are brittle, take a long time to run, and far removed from the services where the logic is.
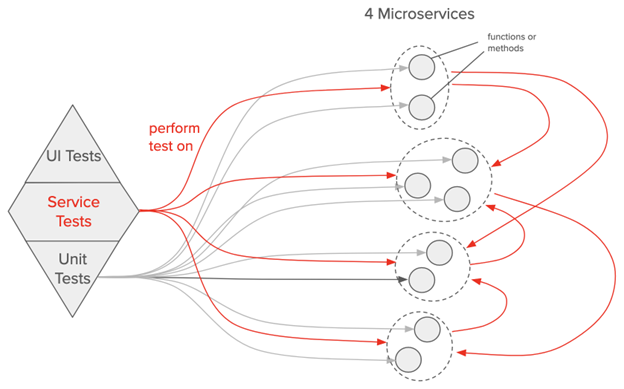
Figure: test diamond and a distributed system. The small circles are functions or methods. The larger dashed circles are microservices.
Andrew leads the development of embedded software for a suite of complex products that must be highly reliable. He has found that for their products, the testing “pyramid” should instead be a testing “refrigerator” – that to manage risk and make sure that the system does not have any internal or user level glitches, they need to have approximately equal coverage of every scope of test, from unit up through UI level.
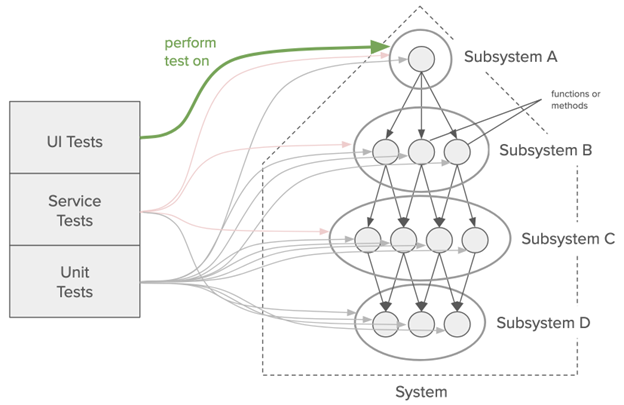
Figure: testing “refrigerator” and an embedded system. The small circles are functions or methods. The larger gray circles are subsystems.
So it depends on the system. Testing should not be a pyramid: one should assess how much risk is reduced by each level of testing for the system you are working on. It is situational.
Small changes are not inherently better: balance is needed
While CD helped us a lot because it made us test from the start instead of at the end, there are some ideas that have arisen in the DevOps community that are not quite right. For example, there is a popular set of metrics known as the “DORA” metrics. The main ones are:
- Change lead time.
- Deployment frequency.
- Change fail percentage.
- Failed deployment recovery time.
These are all highly biased toward Internet-based applications. But putting that aside, while numbers 1, 3, and 4 work well, maximizing deployment frequency can be counter-productive, encouraging many code commits and deployments. Perhaps too many.
One might argue that this will be checked by number 3: that if there are failures, then the deployment frequency will slow down. But in practice people are encouraged to make lots of tiny changes.
Yet tiny changes are often not what is needed. Not all software changes should be incremental. DORA metric number 2 is amplifying a culture of small incremental changes instead of thoughtful design, begun by eXtreme Programming. This can easily turn into a culture of bandaids rather than deep fixes.
This is an example of how easily ideas in the Agile community are taken to an extreme: if A is good, then more A must always be better. DORA metric 2 is a good one, except for the fact that people view it as if “more is always better”. That is not the case: it always depends. There are tradeoffs.
We do not want an extreme culture of small incremental changes instead of thoughtful design.
A case can be made that Test-Driven Development (TDD) started encouraging tiny incremental additions to code, instead of thoughtful revisions that consider the whole. The claim has been that people will refactor; but in practice, people tend to not refactor very much at all – it’s too much work, and so many unit tests would have to be rewritten!
So we end up with patchwork systems. Andrew has very compelling and concrete evidence of this, taken from the public repositories of companies like Google and Amazon.
To be fair, TDD was a much-needed push-back on the prevalent approach of the time, which was to create big releases. Big releases are just as bad as tiny increments – perhaps worse. But we have gone too far toward tiny releases – it has become ideological. We have leaped from the pot into the fire. Balance is needed.
TDD was a push-back on the prevalent approach of the time, which was to create big releases – but we have gone too far the other way.
TDD or not, broad architectural changes cannot – should not – be done incrementally, because that creates a mess until you are done.
Imagine workers tearing down walls one-by-one in your house, in small increments. The architecture changes that you could consider would be limited.
Imagine workers rearchitecting your house in small increments, tearing down walls and putting up new ones one-by-one in. They promise to “not break the house” and always keep it in a usable state, but there will be periods of time in which to get to the kitchen you have to walk outside and around to the back, stepping over tools and debris: the layout will be a mishmash and it will completely lack cohesion until the changes near completion.
All that work-in-progress invites confusion and errors – and security vulnerabilities. Code littered with feature flags is confusing and is therefore untrustworthy code.
A culture of tiny changes has created a culture of thinking narrowly.
A culture of tiny changes has created a culture of thinking narrowly – of not designing things at a system level. How can you, if you only make one small change at a time? – you are not able to make big scaffolding changes that break everything, so you avoid those, compromising the architecture change that needs to occur.
Consider for example when Amazon Prime Video changed the architecture of their monitoring service from a microservice architecture to a monolith. That change crossed the boundaries of many repositories. There is no way that could have been done in small increments.
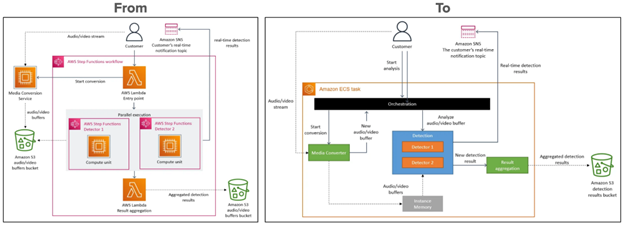
Figure: a “from” system architecture and a “to” system architecture, for a distributed system. This is the Amazon monitoring service.
Having a thousand microservices with no plan for who uses them and how they all work together is not a defensible version of system engineering. And when changes are made to a company’s services, all of the users of those services must be tested.
No, the services are not truly independent – they are all logically coupled, and there are many system level failure modes that cannot be seen if one only looks at the system one service at a time – especially if the services each create their own transaction. Also, service APIs are notoriously ambiguous and type-unsafe.
Services are not truly independent – they are all logically coupled.
We don’t want to bring back the big detailed up front design, but an up front sketch of how things will work is crucial. Astute programmers do that, but among the less experienced, there is now a culture of jumping to coding without designing.
We need to replace a culture of “coding” with a culture of engineering, and that includes a culture of engineering-like testing.
Yes, a lot of design happens during coding, but starting coding without a well thought-out design is a prescription for a hack-job. Instead of code reviews, we should have design reviews. And instead of a thousand unit tests, maybe we should have a well-conceived plan for how the system will be tested – but automatically, at scale, from the start.
We also need to remember that the goal is not testing, but system validation, so we should be open-minded about alternatives to testing, for example as in the “software clean room” approach that we mentioned above. Cliff has had great results by simply designing algorithms in a document, mentally verifying them, and then translating them to code. Using that approach, a bug has never appeared in code created that way – and the code has always worked the first time.
A testing strategy documents what we intend to do, and then we try it and see how well it works.
“Programmers test their own code” – uh, no they don’t
Then there is the view that “programmers test their own code”. That comes from the assumption that the programmers are using TDD. But most are not: TDD is not the most common approach used by programmers. And as we explained, today’s distributed systems need more integration tests than unit tests. Are programmers the best people to design the integration tests?
To some extent, yes: programmers understand the system, and the ways that it can fail. But programmers do not have the best understanding of the business requirements.
Also, application programmers are not the best people to write tests, which is psychologically an opposing goal. An application programmer’s desire is that their code will run. A tester’s desire is that they will find a problem. These are opposing goals in terms of intent and desire. That’s why a programmer writing application code and someone writing tests for that code have opposite mindsets.
Application programmers and test programmers have opposing mindsets. That’s why people cannot test their own code well.
The reality is that people writing integration tests have a different mindset than programmers writing the product’s software, and the mindset is important. That’s why, for large systems, it is very advisable, from a risk management perspective, to have separate people write the integration tests.
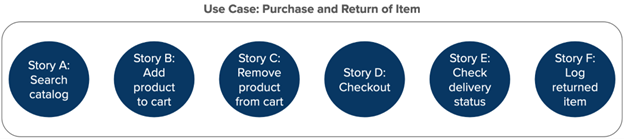
Figure: Six stories. Tests of the stories are insufficient: one must test entire use cases as well.
Tests of the stories are insufficient: one must test entire use cases as well.

Figure: use case level tests that would be missed if only stories are thought of.
Finally, there is the Agile bias toward story level tests, popularized as Behavior-Driven Development (BDD). We think that BDD is powerful, but story level tests are not enough.
Stories have been overemphasized. The emphasis on story level tests is a result of the emphasis on Scrum sprint backlogs, which consist of work items that most people refer to as “stories” (Scrum calls them “sprint backlog items”). Tests of a story’s function are crucial, but insufficient. There also need to be larger scope tests from a user’s perspective – for example “use case level” tests that test an entire sequence of actions toward performing a function with the system.
All these kinds of testing can easily snowball into too many tests – so many that the cost of development goes way up. That’s why a test strategy is crucial, to balance the kinds of tests (e.g. unit, component, logical integration, cloud integration, performance…) with the goal of reducing risk in an optimal way. More is not always better. We need the right amount of each kind of test for each system.
What Does All This Mean?
All this means that a new baseline is needed for agile testing. What we have is outmoded, opinionated, based on false assumptions, and somewhat ideological.
We need to start from a risk management perspective.
Begin each initiative by creating a test strategy table.
I teach DevOps, by instructing product leaders to begin each initiative by creating a table that they build with their teams. Each row in the table is a type of test. Then in each row, one identifies the reason for the test, and what tools and techniques will be used to create or perform the tests. Tests should be automated wherever possible and ideally it should be possible to run every test in any kind of environment, so that, for example, people can run integration tests and even performance tests locally as long as they are able to mock things (substitute simulated components) or deploy things “locally” (to a developer-controlled test environment or even their own computer). Tying tests to environments or environment-specific tools is very limiting.
In each row of the table, one also lists how coverage will be assessed: that is, how we know that we are doing enough.
Don’t copy the sample tables: each system is different. Use the idea, and create your own tables.
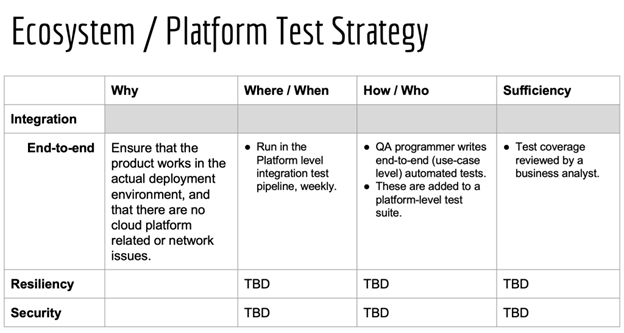

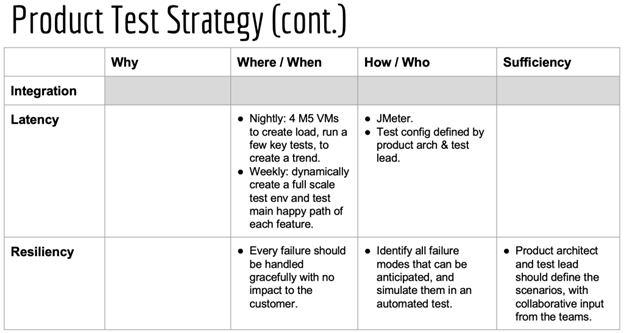

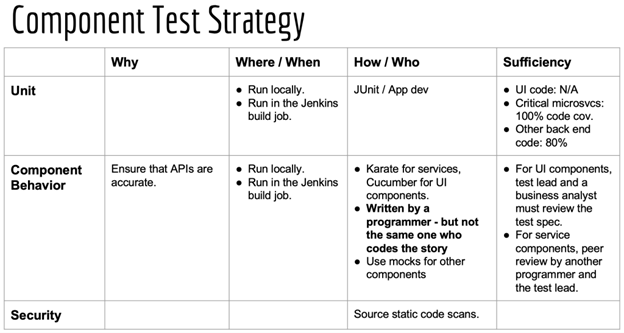
Figure: Sample initial skeletal test strategy tables, for the integrated product running on the platform, for the product itself, and for the components of the product. Over time, the teams fill in the rest of the strategies. Source: Hyper DevOps course, by Agile 2 Academy.
For unit tests, one can use a test coverage proxy called “code coverage”, but for all other kinds of tests, there is no numeric. Instead, one has to list a strategy for ensuring enough coverage. For example, to ensure coverage for integration tests, one could specify a practice of having a test lead examine the test scenarios, and add more if they are not sufficient (or remove some if there are too many), appropriate for the system. For business-centric features, one could have a business analyst review the scenarios. And these should be done in a way that does not cause anyone to wait: we do not want to recreate a waterfall approach. Avoiding waiting is easy because test scenarios for a feature can be written during development but just before work starts on the feature.
We also need to revisit the test pyramid. It’s not right – not anymore. We need a risk-based approach.
What do you think? We would love to hear from you. Please think from first principles – not from established narratives about what is best. Let’s reimagine agile testing!
Article by Cliff Berg and Andrew Park