Estimation is a major activity for traditional systems such as building design and construction, and also engineering routine items such as toasters and washing machines, but estimation fails pretty spectacularly for software and for high-tech engineering.
For example, today there was this post in the Reddit “subreddit” (topic) on Scrum:
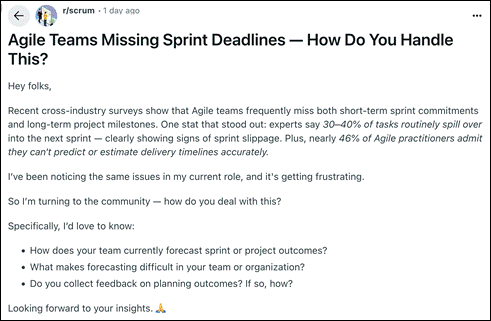
This person is struggling to understand why people cannot accurately estimate software work. Let’s examine why that is – why it is, in fact, impossible. This is also true for the engineering of cutting-edge things.
Let’s start by considering programming; I’ll then expand to engineering.
What Programming Consists Of
Programming consists of defining an algorithm that satisfies the requirements.
The amount of work required is determined by,
- The size of the algorithm.
- The complexity of the algorithm, since it needs to work together.
- The difficulty of uncovering the true behavior (and often undocumented) of third party components that are needed by the algorithm.
- The difficulty of uncovering obscure but important requirements that might not be known at the outset.
However, each of these activities is largely unknown ahead of time. In fact, if you are able to do activity one, you are done, because you only know how big the algorithm is once you have defined the algorithm. But the code _is_ the algorithm, so if you figure out how big it is, then the algorithm must exist – you must have completed it – and so the code is done.
There is also the reality that a given set of requirements can be satisfied by more than one algorithm. If one were to take a set of software requirements and have two different teams of programmers implement it, and then graph the structure of each solution, one would end up with two graphs. These might look like the two graphs below.
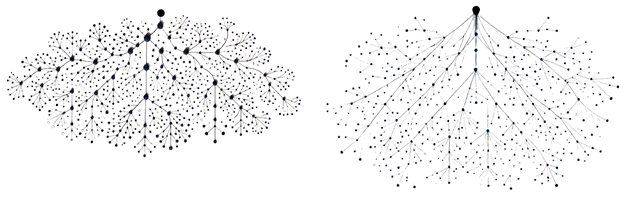
These are different sizes, with different paths, yet each would satisfy the requirements. As they say, “There is more than one way to skin a cat”. (I hate that metaphor because I love cats, but it makes the point.) Each algorithm might be correct, but different from the other – perhaps substantially different. This is analogous to there being more than one path for driving to a given destination – indeed, there might be more than one way to travel to a given destination, perhaps using different forms of transportation.
But the difference between traveling and programming is that whereas to travel somewhere, there is a difference between planning a route and actually traveling the route; but in programming, there is no difference: the code _IS_ the plan: once you have fully planned how the solution will work, you are done, because the code is the plan.
If you have defined the algorithm, you are done – the code is the algorithm!
In programming, all the work is in the creation of the algorithm – the plan. That’s the task. That is what consumes the effort. A high level software design is merely an incomplete algorithm: you have done some of the algorithm design work, and decided to stop at a high level.
One cannot know the algorithm’s full size beforehand, just as when planning a travel route, one cannot know how many turns or changes of platform one will make before actually planning the route.
It Is Not Hopeless
This might be disheartening because the implication is that a software effort cannot be estimated. It can though, with some uncertainty. It turns out that people who have experience doing this can often make a very reliable guess about the ultimate effort, simply based on their brain’s neural network’s prior training – their experience which produces a “gut feeling” about the effort required. It will have uncertainty though – probably a 30% level of uncertainty on average, with outliers as well.
Another hugely important fact is that experienced people tend to be consistent in their inaccuracy. Let me explain. Suppose I estimate a complex programming task, and I underestimate by 20%. If you give me ten tasks to estimate over time, I will tend to be consistent in how much I overestimate: that’s my bias. The bias tends to be fairly consistent over time, especially if you average it. That means that having people estimate most valuable for being able to predict the total overall progress – if you adjust for their historical bias.
You Can’t Know What You Don’t Know
Usually the greatest source of uncertainty has to do with numbers 3 and 4 above, especially number 4. What happens is that as one starts to delve into the nuances of what is required, people discover things that were not known up front. For example, suppose one is programming a system to enroll new customers. During development it might be discovered that customer names must be in Unicode in order to accommodate customers with non-English names, and that presents a challenge in how to scan the names for malicious executable content. The situation then is that what was expected to be a simple aspect of the work balloons into something much larger. There can be lurking oversights like this that greatly expand the effort needed to satisfy the requirements.
Number 3 can also be a great source of uncertainty. Today nearly all software contains myriad third-party components. However, those components are often ambiguously documented. This is true even for professional software systems. A great example is the software suite provided by the widely used payment processor Stripe. Its software APIs are extensive and come in many varieties to accommodate different software languages. However, I know from experience that it contains many ambiguities and so what happens is that a programmer ends up searching the Internet to try and find answers to why code that looks like it should work does not.
That is a common situation – it is not an outlier. Non-programmers think that programmers spend most of their time coding. In reality, programmers spend the vast majority of their time stumped, trying to figure out why their code does not work. And once they fix the program, the code then fails somewhere else. This is an arduous process that continues until the code fully works and passes all of its tests. In the end, 10% of the time was spent coding – perhaps even less – and the rest was spent trying to solve problems related to numbers 2, 3, and 4 above.
Programmers spend the vast majority of their time trying to figure out why their code does not work.
Programming is not like building a building, where the volume of what needs to be done can easily be visualized, and the steps needed can be listed. Software is different every time: if it were not, then you would be needlessly recreating the same program. Programming is non-deterministic. It is highly creative: there is judgment at every step – judgment that affects the direction and size of the algorithm. There is also enormous creativity in one’s solution – the algorithm one creates to solve the problem. The algorithm can be clever, or it can be clear and easy to maintain; or if it is exceptionally well designed, then it can be both clever and clear.
Engineering
Engineering high tech systems is like this too. Engineering is mostly about design. Engineers do not set out to build things: they set out to design them. Engineers build test versions of what they design, but the real versions are manufactured by others. The engineers produce only the design. And like programming, most of their time is spent refining and getting the design to represent a product that will work as required. Once the design fully works, they are done, and knowing the full scope of the design requires a completed design: one cannot have one before the other.
That said, experienced engineers can make reliable estimates of how long it will take to create and validate a design. For systems that are routine like a typical building or anything that is similar to what you have done before, estimation can be pretty spot-on; but high tech systems tend to be cutting edge and therefore you have not done it before, and so it will have that 30% uncertainty, with outliers.
They could not know up front how many tests would be needed, or how many design changes would be needed. Knowing that would mean that the design was done.
A great example is the rocket being designed by SpaceX right now. They have been refining their design and testing it, but the most recent three launches resulted in the loss of the rocket. They have had to adjust the design each time. They could not know up front how many tests would be needed, or how many design changes would be needed. Knowing that would mean that the design was done.
Thus, for engineering, one cannot accurately estimate the effort required – that uncertainty level is unavoidable, and it is just a guess: there is no scientific way to refine the estimate, for the reasons that I have explained. It would be like trying to cheat the second law of thermodynamics: to decrease entropy. Designing something is the process of creating information, and one cannot predict how much information will be created: if one could, one would have already created the information.
What About Practices for Estimation?
There is a wealth of material written on techniques for how to estimate software and engineering. Those techniques can be useful, but here’s the thing:
In using those techniques, one has to do the system design to a certain level. That’s because those techniques all rely on decomposing the system’s function – its algorithm – into smaller and more estimable units.
Thus, the process of estimation is actually a design process! It takes effort, and you are doing part of the work of coding the system! That’s okay: we just need to recognize this: estimation using decomposition techniques is not separate from system implementation: such estimation must perform some of the algorithm design – some of the coding work – even if the result is not code, but is a block diagram.
Also, it does not eliminate the uncertainty: numbers 2-4 still exist, and they are great sources of uncertainty. Just because you have decomposed a system does not mean that you have eliminated all of its unknowns: you have only reduced their likelihood. There can still be lurking issues that will only be discovered as implementation proceeds.
The Upshot
This means that when building software or high tech systems, we need to accommodate uncertainty, and match it to our risk tolerance, rather than trying to eliminate it. It means that we need to make most deadlines aspirational, rather than fixed. It means that for the few remaining fixed deadlines, we need to be flexible about the details and focus on those requirements that are truly necessary. It means that we need to allow the design to evolve, since as we have seen, if we knew what the design would end up being, then we would be done.
It means that we need to be ready to adapt, and to do so without delay. This implies a continuously adjusting process, rather than one that progresses through a cadence. A cadence implies steady progress, like digging a trench or putting up the floors of a building; but given software’s non-deterministic nature, we need a just-in-time process, whereby we are always watching, ever ready to recognize when a change in direction is called for. We need to not wait: we need to notice issues as they arise, and discuss and resolve what to do right away, rather than dealing with it in the next scheduled meeting. It means blending strategic and tactical decision-making: keeping strategic and tactical issues separate, but always ready to adjust either.

Cliff is Managing Partner of Agile 2 Academy. As a successful tech entrepreneur, he was co-founder and CTO of Digital Focus, a startup that grew from 2 to 200 people in five years and was known for its success in rapidly building high reliability Internet-facing business critical systems for companies like FedEx, McKesson, United Overseas Bank, and many others. It was acquired in 2006. Cliff’s 2006 textbook High-Assurance Design documents many of the engineering and agility lessons learned. Since then Cliff has helped with more than ten Agile or DevOps transformations, and is a DevOps trainer and subject matter expert. In 2020 Cliff assembled the global Agile 2 team to reimagine “Agile”, and was the lead author of the Agile 2 book. Cliff is certified in the Human Synergistics Organizational Culture Inventory® and Organizational Effectiveness Inventory® assessment tools. He has degrees from Cornell University in Operations Research, Nuclear Engineering, and Physics.